说是要写一篇 DeepSeek 部署的文章发布到公众号上,那么,就顺带这里也发一下吧。
1. DeepSeek 简介
DeepSeek 是一家由中国著名私募巨头幻方量化创立的人工智能公司,成立于 2023 年左右,专注于通用人工智能底层模型与技术研究。公司致力于探索 AI 的本质,其产品涵盖了大语言模型(如 DeepSeek-LLM、DeepSeek-Coder、DeepSeek-V2、DeepSeek-V3 以及最新的 DeepSeek-R1 等)。这些模型不仅在自然语言处理、代码生成、数学推理等任务中表现出色,而且在训练成本和推理效率上实现了较大的突破。例如,DeepSeek-R1 模型在保证高性能的同时,训练成本仅为数百万美元,而相比之下国际上某些顶级模型的成本可能高出数倍甚至十倍以上。
2. 对系统运维工作的赋能
借助 DeepSeek 系列模型在自然语言理解、逻辑推理和大数据分析方面的优势,其技术在系统运维工作中具有广泛的应用潜力,主要体现在以下几个方面:
-
智能故障分析
利用模型强大的文本理解与推理能力,可以对日志数据、告警信息、系统监控数据等进行自动归纳和关联分析,从而快速定位故障原因,优化排查流程,提高运维效率。 -
异常检测与预测
通过对系统日志、资源消耗、网络流量等数据的实时分析,DeepSeek 可以识别异常模式,提前预警潜在故障,帮助运维团队采取预防性措施,降低系统宕机风险。 -
知识库自动构建
结合深度学习技术,模型可以从历史运维记录、故障处理文档、技术论坛等信息源中提取关键知识,自动构建运维知识库,提升新手运维工程师的学习效率,并为问题解决提供智能建议。
这些应用有助于实现运维工作的自动化和智能化,提高系统的稳定性和可用性,优化资源配置,并进一步提升 IT 基础设施的运营效率。
3. 不同参数的含义与区别
在 DeepSeek 的模型设计中,参数设置既是衡量模型复杂度的重要指标,也是平衡计算效率与性能表现的关键。常见的参数及其含义如下:
-
总参数量
指模型中所有参数的总和,反映了模型的整体容量与表达能力。例如,DeepSeek-V3 的总参数量达到 671B(即 6710 亿个参数),这表明其拥有极高的学习和表达潜力. -
激活参数量
对于采用 MoE(混合专家)架构的模型来说,并非所有参数在每次前向计算中都会被使用。激活参数量指的是在一次推理过程中实际参与计算的参数数量。以 DeepSeek-V3 为例,虽然其总参数量很大,但每个 token 的计算只激活大约 37B 的参数,这种设计大大提高了计算效率,降低了内存占用. -
专家参数设置
在 MoE 架构中,模型通常包含两类专家:- 共享专家:始终参与计算,负责捕捉普遍性的知识和信息。
- 路由专家:根据输入数据动态激活,专注于特定领域或任务的知识。这种分工使得模型既能保持高容量,又能在推理时实现高效计算和资源利用.
-
不同规模版本
DeepSeek 还提供了从 1.5B、7B、8B、14B、32B、70B 到 671B 等多个版本。这些版本在参数量上有显著差异,适应不同的硬件环境和应用场景。较小规模的模型便于在资源有限的场景下部署,而大规模模型则适合追求更高精度和复杂任务处理的应用.
通过这些参数的合理设置和差异化设计,DeepSeek 实现了在保持模型高性能的同时,大幅度降低计算资源消耗,从而为各类应用场景(包括警务、企业服务等)提供了高效、经济的解决方案.
4. DeepSeek 模型部署
本节详细介绍 DeepSeek 模型在服务器环境下的部署过程,主要包括部署环境准备、NVIDIA 驱动与 CUDA 的安装,以及 DeepSeek 运行环境的搭建。
4.1 部署环境
本次部署环境配置如下:
- 操作系统
使用 Ubuntu 24.04.1 Live Server 版(安装镜像文件:ubuntu-24.04.1-live-server-amd64.iso)。 - GPU
部署服务器配备 4 块 NVIDIA A40 显卡(NVIDIA A40 x4)。 - NVIDIA 驱动
使用驱动包:nvidia-driver-local-repo-ubuntu2404-560.35.03_1.0-1_arm64.deb。 - CUDA 环境
对应 CUDA 安装包:ubuntu-24.04LTS-cuda_12.6.0_560.28.03_linux.run。 - 服务器硬件
- CPU:Intel® Xeon® Silver 4310 CPU @ 2.10GHz
- 内存:256GB DDR4 3200MHz
- DeepSeek 模型文件
模型文件命名为deepseek-(具体版本根据实际情况选择,如 DeepSeek-V3、DeepSeek-R1 等)。 本次部署选择DeepSeek-R1-Distill-Llama-70B模型 - 其他必须条件
- 服务器互联网连接「为了处理 apt 软件源问题,离线安装请准备好完整的离线 Ubuntu 软件源」
- Python 相关依赖,建议联网,通过互联网安装
4.2 前置条件及运行环境准备
在部署 DeepSeek 模型之前,请确保完成以下准备工作:
-
模型文件下载
从 DeepSeek 官方网站或 GitHub 仓库下载对应版本的模型文件,确保文件完整且未损坏。 下载地址https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B需要下载所有文件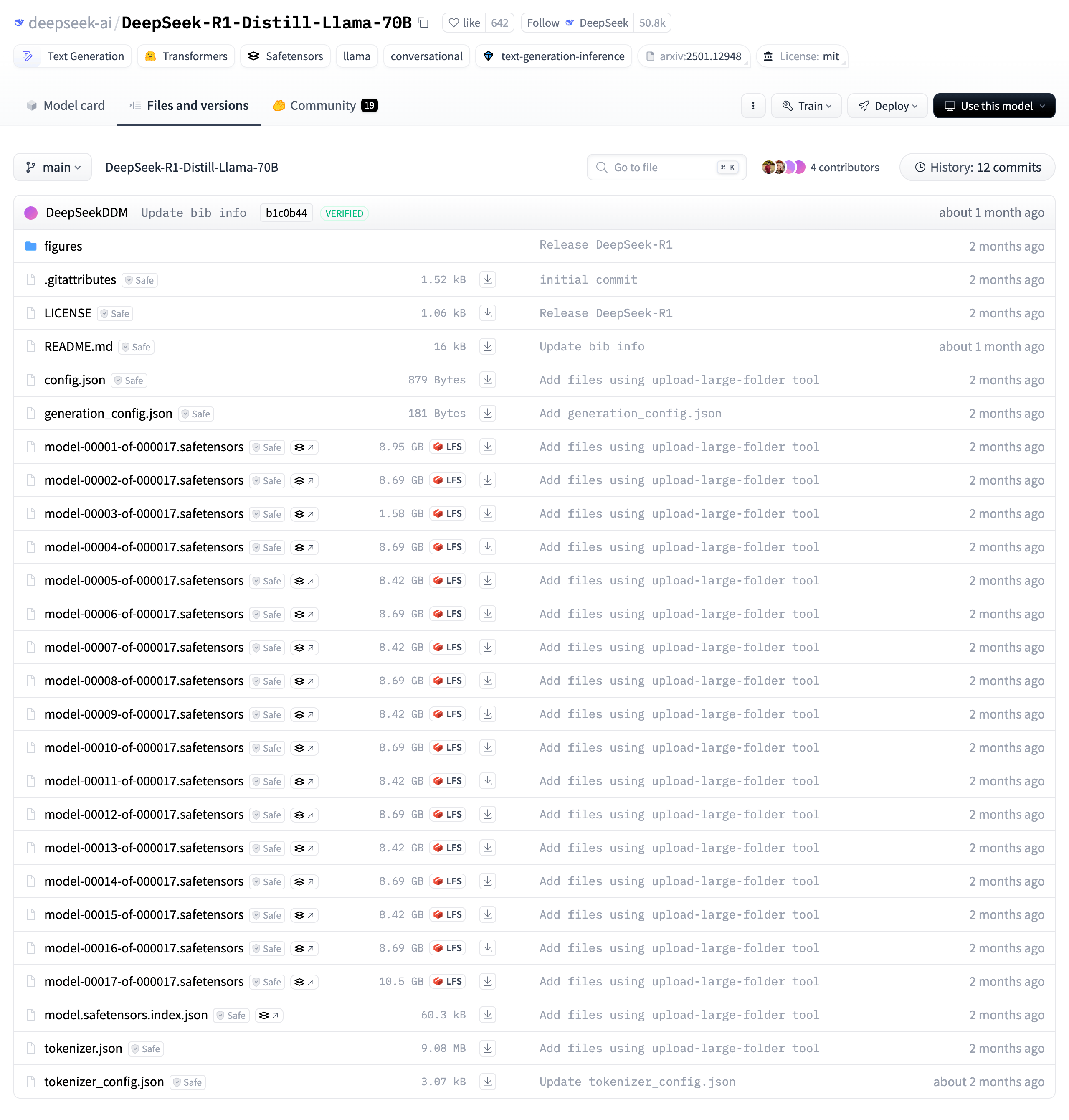
-
NVIDIA 驱动下载
从 NVIDIA 官方网站获取对应 Ubuntu 24.04 系统版本的驱动安装包。 下载地址https://www.nvidia.com/en-us/drivers/按需选择对应驱动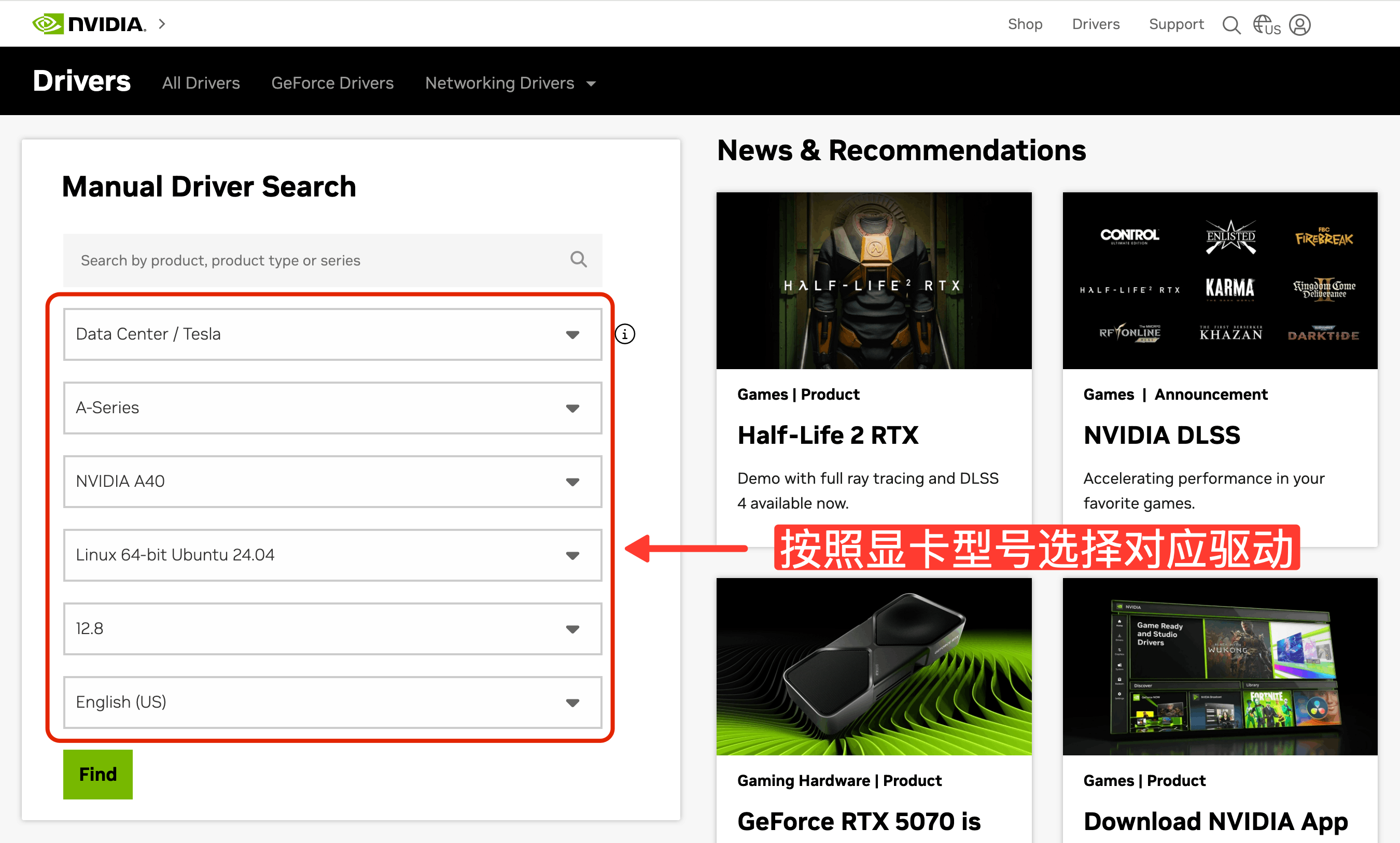
-
CUDA 工具包下载
下载与驱动版本匹配的 CUDA 工具包安装文件,确保 CUDA 环境能够支持 GPU 加速。 下载地址https://developer.nvidia.com/cuda-toolkit-archive按需选择对应工具包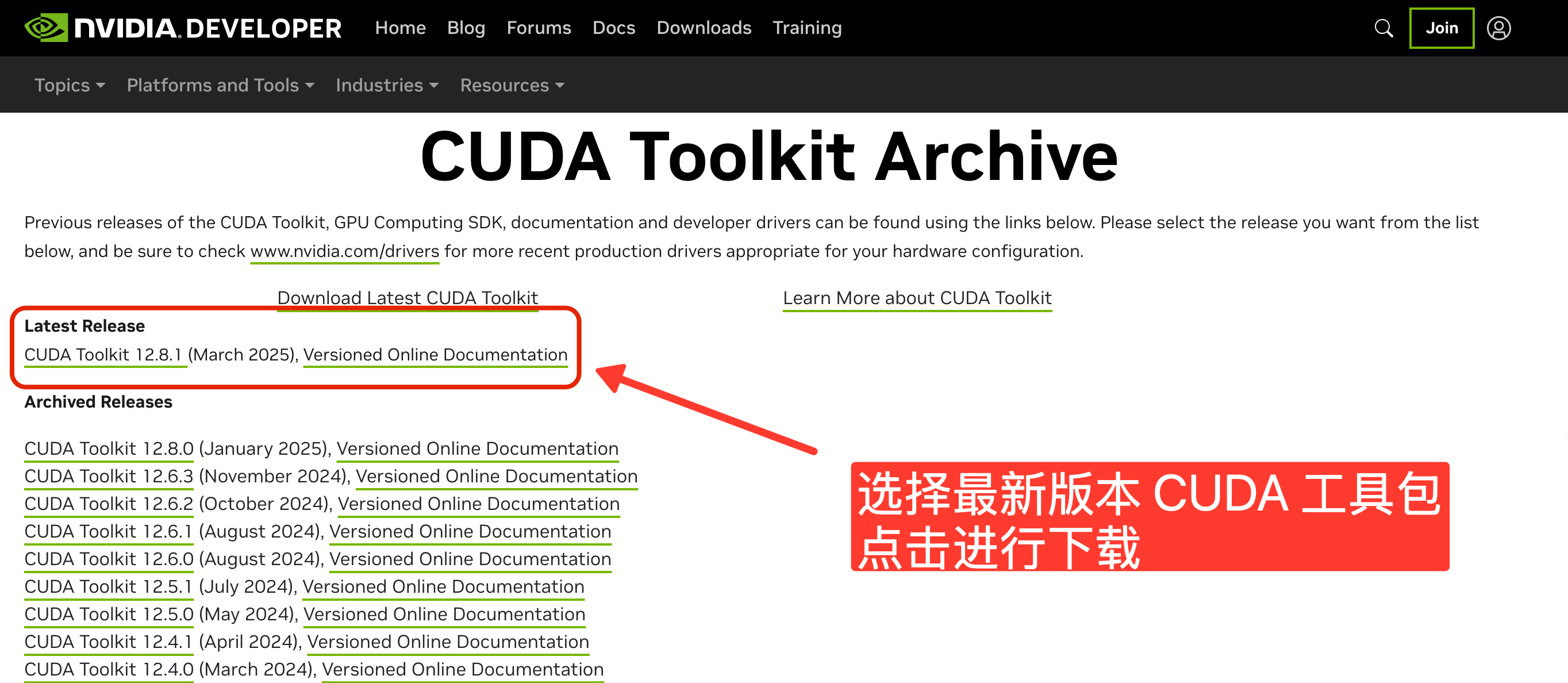
-
Python 环境准备
安装 Python 3.8 及以上版本,并创建虚拟环境(如使用 Conda 或 virtualenv),安装必要的依赖包(如 PyTorch、transformers、CUDA 相关库等)。 下载地址使用 pip 进行安装
pip install torch torchvision torchaudio transformers
4.3 NVIDIA 相关驱动及 CUDA 部署
请确保 服务器 有 GCC 环境
- 驱动安装
- 将下载好的 NVIDIA 驱动
.deb包上传至服务器,使用dpkg -i <driver-package.deb>命令进行安装。 - 根据提示安装依赖并重启系统,确保新驱动加载成功。
- 之后使用
apt安装驱动apt install nvidia-openapt install cuda-drivers - 安装完驱动后务必重启
reboot操作系统,否则 nvidia 驱动不会启动
- 将下载好的 NVIDIA 驱动
- CUDA 安装
- 上传 CUDA 安装文件至服务器,给予执行权限(例如
chmod +x ubuntu-24.04LTS-cuda_12.6.0_560.28.03_linux.run)。 - 执行安装程序,根据提示完成安装。安装过程中建议选择自定义安装,确保正确配置环境变量(如 PATH 和 LD_LIBRARY_PATH)。
- 安装完成后,重启系统并通过
nvcc --version命令验证 CUDA 环境是否安装成功。
- 上传 CUDA 安装文件至服务器,给予执行权限(例如
驱动安装完后可通过 nvidia-smi 查看到驱动版本和 CUDA 版本。
# 使用 nvidia-smi 命令验证驱动是否安装成功,如有类似下方输出即为安装成功
root@ubuntu:~# nvidia-smi
Mon Feb 10 03:48:48 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A40 Off | 00000000:67:00.0 Off | 0 |
| 0% 30C P8 20W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA A40 Off | 00000000:68:00.0 Off | 0 |
| 0% 31C P8 21W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA A40 Off | 00000000:6C:00.0 Off | 0 |
| 0% 29C P8 22W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 3 NVIDIA A40 Off | 00000000:6D:00.0 Off | 0 |
| 0% 28C P8 13W / 300W | 1MiB / 46068MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
CUDA 安装完后可通过 nvcc --version 查看是否安装成功。
# 使用 nvcc --version 命令验证 CUDA 环境是否安装成功,如有类似下方输出即为安装成功
(base) root@ubuntu:/home# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Aug_15_22:02:13_PDT_2023
Cuda compilation tools, release 12.6, V12.6.140
Build cuda_12.6.r12.6/compiler.33191640_0
流程图
graph TD;
A[驱动安装] --> B[上传 NVIDIA 驱动 .deb 文件到服务器];
B --> C[使用 dpkg -i <driver-package.deb> 进行安装];
C --> D[安装依赖并重启系统];
D --> E[使用 apt 安装 nvidia-open 和 cuda-drivers];
E --> F[重启系统以加载驱动];
G[CUDA 安装] --> H[上传 CUDA 安装文件到服务器];
H --> I[给予执行权限 chmod +x <安装文件>];
I --> J[运行安装文件并进行自定义安装];
J --> K[确保配置 PATH 和 LD_LIBRARY_PATH];
K --> L[重启系统];
L --> M[运行 nvcc --version 验证安装成功];
F -->|驱动安装完成| G;
4.4 DeepSeek 运行环境准备
-
依赖安装
-
在已创建的 Python 虚拟环境中,使用 pip 安装必要的依赖包,例如:
pip install torch torchvision transformers pip install numpy scipy -
如有 DeepSeek 提供的专用依赖包,请参照官方文档进行安装。
-
-
环境变量配置
-
确保 CUDA 和 cuDNN 的环境变量已正确设置,例如在
.bashrc文件中添加:export PATH=/usr/local/cuda-12.6/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH -
保存后执行
source ~/.bashrc使配置生效。
-
-
测试环境
-
编写简单的 PyTorch 测试脚本,检查 GPU 是否能被正确调用,有输出就可以:
import torch print(torch.cuda.is_available()) print(torch.cuda.get_device_name(0))
-
-
模型环境
请确保已下载如下模型文件
⚠️ 注意:请务必完整下载 huggingface.co 上完整项目,本次 DeepSeek-R1-Distill-Llama-70B 模型至少需要下方文件
root@ubuntu:/data/DEEPSEEK# ls -1
config.json
generation_config.json
model-00001-of-000017.safetensors
model-00002-of-000017.safetensors
model-00003-of-000017.safetensors
model-00004-of-000017.safetensors
model-00005-of-000017.safetensors
model-00006-of-000017.safetensors
model-00007-of-000017.safetensors
model-00008-of-000017.safetensors
model-00009-of-000017.safetensors
model-00010-of-000017.safetensors
model-00011-of-000017.safetensors
model-00012-of-000017.safetensors
model-00013-of-000017.safetensors
model-00014-of-000017.safetensors
model-00015-of-000017.safetensors
model-00016-of-000017.safetensors
model-00017-of-000017.safetensors
model.safetensors.index.json
tokenizer_config.json
tokenizer.json
5. 启动模型
# 使用 vllm 启动模型
CUDA_VISIBLE_DEVICE=0,1,2,3 /opt/Python/bin/python3.8 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 11435 --gpu-memory-utilization 0.9 --model /data/DEEPSEEK/DeepSeek-R1-Distill-Llama-70B --max-num-seqs 5 --max-model-len 30000 --enable-prefix-caching --enable-chunked-prefill --served-model DeepSeek-R1-Distill-Llama-70B --tensor-parallel-size 4
# 模型参数说明
--host 0.0.0.0 监听所有网卡,允许外部访问。
--port 11435 服务器监听的端口号,API 服务器将在 11435 端口提供服务。
--gpu-memory-utilization 0.9 设置 GPU 显存的使用率上限为 90%,防止超载导致 OOM(Out of Memory)。
--model /data/DEEPSEEK/DeepSeek-R1-Distill-Llama-70B
指定加载的模型路径(DeepSeek-R1-Distill-Llama-70B)。
--max-num-seqs 5 允许最多 5 个并发请求序列,提高吞吐量。
--max-model-len 30000 设置模型的最大 token 长度为 30000(即最大上下文长度)。
--enable-prefix-caching 启用 前缀缓存,加速具有相同前缀的推理请求,减少重复计算,提高性能。
--enable-chunked-prefill 启用 分块预填充,适用于长文本输入,加快处理速度。
--served-model DeepSeek-R1-Distill-Llama-70B
公开 API 端点使用的模型名称,API 客户端需要在请求中指定此模型名称。
--tensor-parallel-size 4 设置 张量并行(Tensor Parallelism)级别为 4,将模型拆分到 4 张 GPU 上并行计算,提高推理效率。
6. 模型快速验证
请依照下方操作,快速验证模型可用性
# 验证程序
root@ubuntu:/data/PROGRESS# cat test-v3.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 指定 DeepSeek 模型路径
model_path = "/data/DEEPSEEK"
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 进入推理模式
model.eval()
# 测试输入
question = "What is deep learning?"
inputs = tokenizer(question, return_tensors="pt").to(model.device)
# 生成回答
with torch.no_grad():
output = model.generate(
**inputs,
max_length=300, # 增加 max_length,避免回答被截断
temperature=0.7, # 控制回答的多样性
top_p=0.9, # 核采样
repetition_penalty=1.2 # 防止重复
)
# 先解码,再打印
answer = tokenizer.decode(output[0], skip_special_tokens=True) # `skip_special_tokens=True` 避免出现额外的 token
# 打印结果
print("Tokenized Input:", inputs)
print("Generated Output:", output)
print("Decoded Answer:", answer)
# 验证程序执行输出
root@ubuntu:/data/PROGRESS# /opt/Python/bin/python3.8 test-v3.py
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 17/17 [00:37<00:00, 2.23s/it]
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)
Tokenized Input: {'input_ids': tensor([[128000, 3923, 374, 5655, 6975, 30]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]], device='cuda:0')}
Generated Output: tensor([[128000, 3923, 374, 5655, 6975, 30, 765, 18682, 21579,
49107, 369, 91268, 198, 34564, 6975, 374, 264, 27084,
315, 5780, 6975, 430, 18065, 279, 1005, 315, 30828,
14488, 311, 24564, 828, 13, 61577, 14488, 527, 62653,
1306, 279, 3823, 8271, 323, 6824, 315, 13931, 315,
83416, 7954, 477, 330, 818, 54769, 1210, 9062, 6324,
11618, 2038, 304, 264, 72859, 810, 6485, 1648, 11,
10923, 279, 4009, 311, 4048, 12912, 323, 1304, 11429,
627, 644, 420, 22237, 11, 584, 3358, 3493, 459,
17219, 311, 5655, 6975, 19476, 11, 12823, 11, 323,
8522, 369, 47950, 382, 14711, 5422, 76872, 512, 16,
13, 3146, 9470, 16895, 61577, 39810, 320, 12272, 82,
1680, 334, 4314, 527, 55580, 4211, 14948, 555, 24156,
30828, 14488, 13, 2435, 6824, 315, 1988, 13931, 11,
8340, 13931, 11, 323, 2612, 13931, 8599, 1555, 14661,
323, 50183, 382, 17, 13, 3146, 41335, 25, 1035,
256, 482, 3146, 2566, 23570, 68063, 61396, 1924, 279,
2926, 828, 627, 256, 482, 3146, 17964, 84922, 68063,
26050, 6485, 83699, 389, 279, 11374, 26, 11383, 5361,
13931, 42415, 3871, 1376, 264, 364, 33980, 6, 4009,
627, 256, 482, 3146, 5207, 23570, 68063, 53592, 279,
1620, 20212, 477, 1121, 3196, 389, 16674, 505, 279,
1566, 8340, 6324, 382, 18, 13, 3146, 62560, 24460,
68063, 1357, 48945, 2536, 8614, 10981, 1139, 279, 1646,
11, 28462, 433, 311, 12602, 6485, 12912, 13, 7874,
5865, 2997, 1050, 24115, 11, 328, 53211, 11, 25566,
71, 11, 5099, 382, 19, 13, 3146, 38030, 8773,
25, 1035, 256, 482, 3146, 27014, 3998, 28236, 68063,
2956, 28555, 4741, 1555, 1855, 6324, 311, 12849, 20492,
627, 256, 482, 3146, 40938, 75316, 68063, 35204, 1493,
1990, 19698, 323, 5150, 2819, 1701, 4814, 5865, 1093,
95699, 477, 11511, 12, 98682, 627, 256, 482, 3146,
3792, 1637, 3998, 28236, 320, 3792, 2741, 1680, 334,
23426, 53249, 315]], device='cuda:0')
Decoded Answer: What is deep learning? | Deep Learning Tutorial for Beginners
Deep learning is a subset of machine learning that involves the use of neural networks to analyze data. Neural networks are modeled after the human brain and consist of layers of interconnected nodes or "neurons." Each layer processes information in a progressively more complex way, allowing the network to learn patterns and make decisions.
In this tutorial, we'll provide an introduction to deep learning concepts, techniques, and applications for beginners.
### Key Concepts:
6. **Artificial Neural Networks (ANNs):** These are computational models inspired by biological neural networks. They consist of input layers, hidden layers, and output layers connected through weights and biases.
7. **Layers:**
- **Input Layer:** Receives the initial data.
- **Hidden Layers:** Perform complex computations on the inputs; typically multiple layers stacked together form a 'deep' network.
- **Output Layer:** Generates the final prediction or result based on outputs from the last hidden layer.
8. **Activation Functions:** Introduce non-linearity into the model, enabling it to capture complex patterns. Common functions include ReLU, Sigmoid, Tanh, etc.
9. **Training Process:**
- **Forward Propagation:** Data flows forward through each layer to compute predictions.
- **Loss Calculation:** Measure error between predicted and actual values using loss functions like MSE or Cross-Entropy.
- **Backward Propagation (Backprop):** Compute gradients of
后面内容因篇幅原因已截断
7. 对话前端部署
为了方便用户与 DeepSeek 模型进行交互,本次选择 fastgpt 作为对话前端。以下是对话前端的部署步骤:
7.1 下载
-
从 fastgpt 的官方网站或 GitHub 仓库下载最新版本的 fastgpt 源码包。
-
例如,使用 Git 克隆仓库:
git clone https://github.com/fastgpt/fastgpt.git
7.2 安装
-
进入 fastgpt 目录后,安装项目依赖:
cd fastgpt pip install -r requirements.txt -
根据项目文档,检查配置文件(如 config.json 或 .env 文件),确保后端 DeepSeek 模型的 API 地址和端口号设置正确。
7.3 测试
-
启动 fastgpt 前端服务:
python app.py -
在浏览器中访问前端地址「例如:http://localhost:8000」,并尝试发送简单对话请求,确认前端能成功调用后端DeepSeek 模型,并返回响应。
8. 使用
部署完成后,用户即可通过对话前端与 DeepSeek 模型进行交互。基本使用步骤如下:
- 打开 fastgpt 对话页面,在输入框中输入问题或指令。
- 系统将请求发送至后端 DeepSeek 模型进行推理处理。
- 模型返回的结果将实时显示在对话窗口中,用户可根据需求继续交互或调整输入内容。
- 如遇到特殊问题,可通过系统日志或调试工具排查网络、模型调用等异常。
用户可根据具体业务场景(如智能客服、案件分析、情报信息挖掘等)进行定制化的二次开发和集成。
9. 回顾总结
9.1 部署注意事项
-
环境兼容性
请确保操作系统、NVIDIA 驱动和 CUDA 工具包版本匹配,避免因版本不兼容导致模型运行异常。 -
硬件资源监控
部署前建议做好服务器硬件资源的评估,尤其是 GPU 显存和计算性能,确保能满足大规模模型的运行需求。 -
依赖管理
采用虚拟环境隔离项目依赖,避免系统级 Python 库版本冲突。定期检查并更新依赖包,确保安全性和稳定性。 -
安全与权限
在服务器上部署时,请注意防火墙、SSH 访问和系统权限配置,防止未经授权的访问和数据泄露。 -
日志和监控
配置完善的日志记录和监控系统,及时捕捉系统异常和性能瓶颈,便于快速定位和解决问题。